딥시크에서 출시한 R1의 성능이 오픈 AI 성능을 상당량 추격하며 전 세계에 충격을 주면서, 엔비디아 등 미국 AI 빅테크 기업들의 주가가 급락했는데요, 딥시크 R1의 기반인 강화학습 AI와 현재 오픈 AI와의 비교분석을 해보도록 하겠습니다.
기업의 차이점에 대해 궁금해하고 있습니다. 오늘은 OpenAI와 딥시크R1의 핵심적인 차이점을 상세히 파헤쳐보겠습니다.
현재 인공지능 기술이 나날이 발전하면서, AI 시장은 크게 두 갈래로 나뉘어 발전하고 있습니다.
ChatGPT로 대표되는 오픈AI의 혁신적인 언어 모델과, 새롭게 등장한 강자 딥시크 R1이 AI 시장에서 펼치는 흥미진진한 경쟁이 상상이 되시나요?
이 두 AI 기업의 기술력 차이는 마치 체스 게임을 두는 두 명의 그랜드마스터처럼 미묘하면서도 결정적인데요, 최근 AI 기술의 급속한 발전으로, 많은 사람들이 이 두 기업의 차이점에 대해 궁금해 하고 있습니다.
특히 최근 화제가 되고 있는 딥시크R1(DeepSeek-R1)은 강화학습 분야에서 주목할 만한 성과를 보여주고 있습니다.
오늘은 이 두 가지 AI 접근 방식의 근본적인 차이점과 각각의 장단점을 심층적으로 살펴보면서, 미래 AI 발전 방향에 대한 통찰을 얻어보고자 합니다.
강화학습 업그레이드로 놀라운 발전을 이룬 딥시크 R1
딥시크 R1은 뭐가 어떠하길래 세계가 이렇게 들썩일까요~? 그 내용을 알아보기 위해 직접 논문을 해석해 보았습니다.
해당 논문이 궁금하신 분들은 아래의 첨부파일을 다운로드 하시기 바랍니다.
딥시크 R1에 알아보기 위해서는 전 작품인 딥시크 R1 제로에 대해 먼저 알아보아야 하는데요, 그 이유는 딥시크 R1은 전작인 딥시크 R1제로의 문제점을 완하여 업그레이드된 상위 버전이기 때문이에요.
DeepSeek-R1-Zero와 DeepSeek-R1에 대한 내용을 요약하자면, 이 모델들은 대규모 강화 학습(RL)을 통해 훈련된 첫 번째 세대의 추론 모델입니다.
DeepSeek-R1-Zero는 감독된 미세 조정(SFT) 없이 훈련되었으며, 뛰어난 추론 능력을 보여주지만 가독성이 떨어지고 언어 혼합 문제에 직면했습니다.
이를 해결하고 추론 성능을 향상시키기 위해 DeepSeek-R1이 도입되었습니다. 이 모델은 RL 이전에 다단계 훈련과 초기 데이터 세트를 포함하여 성능을 개선했습니다.
DeepSeek-R1은 OpenAI-o1-1217과 유사한 성능을 달성했으며, 연구 커뮤니티를 지원하기 위해 DeepSeek-R1-Zero, DeepSeek-R1, 그리고 DeepSeek-R1에서 파생된 여섯 개의 밀집 모델(1.5B, 7B, 8B, 14B, 32B, 70B)을 오픈 소스 화했습니다.
제시된 성능 지표들은 각각의 모델이 다양한 추론 과제에서 어떻게 수행되었는지를 보여줍니다. 예를 들어, AIME 2024, Codeforces, GPQA Diamond 등에서의 Pass@1 비율과 MMLU, SWE-bench Verified에서의 해결률이 나와 있으며, 이를 통해 각 모델의 정확성과 성능을 비교할 수 있습니다.
위의 논문을 간단히 이해하기 쉽게 요약하자면 딥시크 R1은 전작인 딥시크 R1 제로의 떨어지는 가독성과 언어 혼합 문제를 보완하기 위해 연구개발을 진행하였고, Open Ai o1과 유사한 성능을 달성했다고 나와 있습니다.
여기서 Open AI o1은 2024년 9월 출시된 오픈 Ai의 Chat GPT 최상위 버전이에요.
그것도 오픈 AI인 Chat GPT의 학습방식인 사전학습 (Reinforcement Learning from Human Feedback)과 미세 지도 조정(Supervised Fine-Tuning)이 아닌 초기 챗GPT 초기 모델과 알파고가 진행했던 강화학습으로만 눈부신 발전을 하였기 때문이에요.
또한 현재 오픈 AI 버전의 성능을 위해서는 고성능 메모리인 GPU가 필요한데요, 이로 인해 고성능 GPU 제조처인 엔비디아의 성장이 최근 수년간 비약적인 성장을 하였습니다.
하지만 딥시크 R1은 고성능 메모리 없이 강화학습으로만 눈부신 발전을 한 점인데요, 이 부분이 중요한 이유는 저성능 하드웨어의 한계점을 일종의 소프트웨어 발전으로만 돌파했다는 점에 있습니다.
딥시크 R1 성능 비교
그러면 딥시크 R1 성능은 현재 어느 정도 수준이길래 세상이 들썩이고 있을까요?

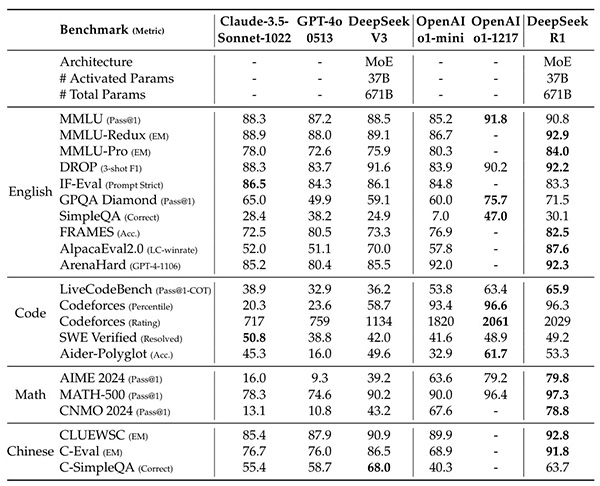
DeepSeek-R1 모델과 다른 대표 모델들 간의 성능 비교에 대한 것인데요, 주요 내용을 요약하면 다음과 같습니다.
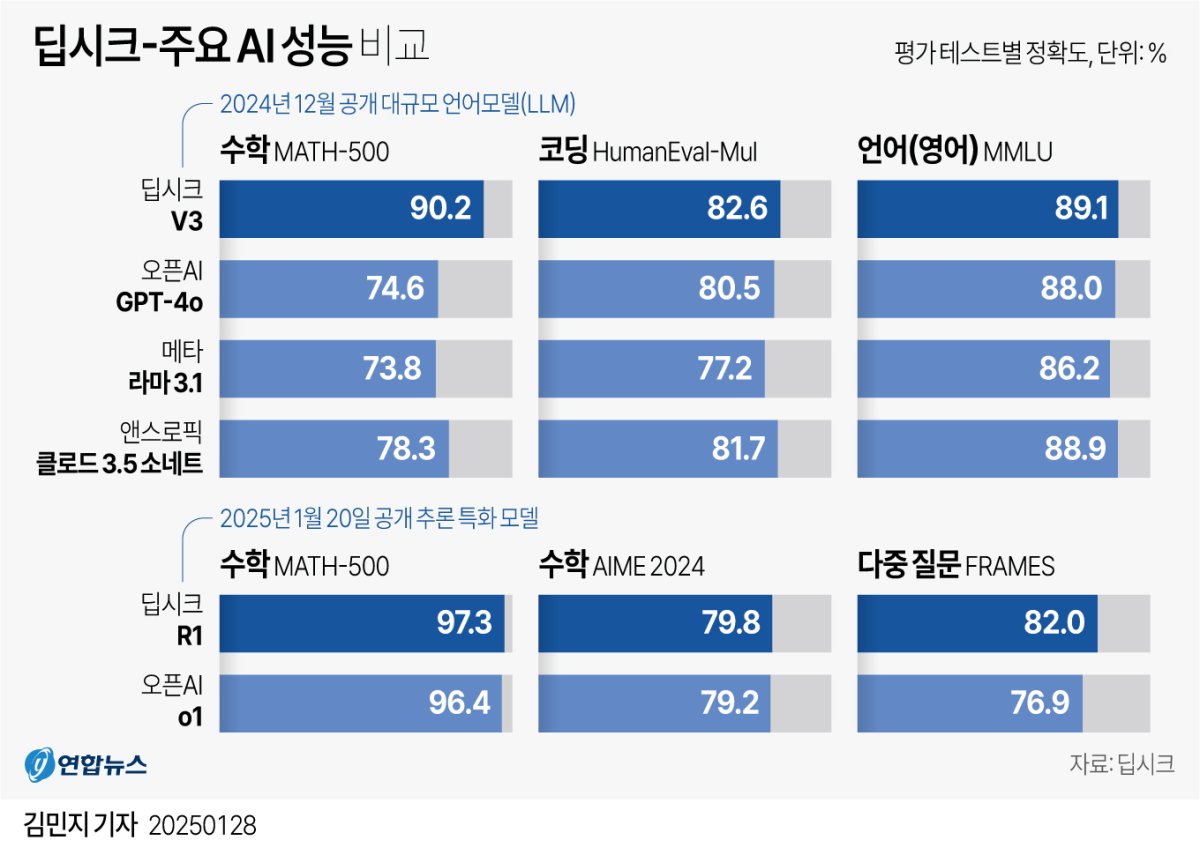
*아래의 이미시 클릭 시, 해당 기사로 이동됩니다. (연합뉴스 참조)
1. 교육 지향적 지식 기준:
MMLU, MMLU-Pro, GPQA와 같은 기준에서 DeepSeek-R1은 DeepSeek-V3보다 우수한 성능을 보입니다. 이는 STEM 관련 질문에서의 정확도가 향상되었기 때문입니다. 이 개선은 대규모 강화 학습을 통해 이루어졌습니다.
2. 문서 분석 능력:
DeepSeek-R1은 FRAMES라는 장기 문맥 의존 QA 작업에서도 뛰어난 성능을 보여주며, AI 기반 검색 및 데이터 분석 작업에서의 추론 모델의 가능성을 강조합니다.
3. 사실 기반 질문 처리:
사실 기반 벤치마크인 SimpleQA에서도 DeepSeek-R1이 DeepSeek-V3보다 우수한 성능을 보입니다. OpenAI-o1은 이 기준에서 GPT-4o보다 더 좋은 성과를 기록했습니다.
그러나 DeepSeek-R1은 중국어 SimpleQA에서는 DeepSeek-V3보다 성능이 떨어지며, 이는 안전 강화 학습(RL) 후 특정 질문에 대한 응답을 거부하는 경향 때문입니다. 안전 RL이 없을 경우 DeepSeek-R1은 70% 이상의 정확도를 기록할 수 있습니다.
4. 형식 지침 준수 능력:
IF-Eval 벤치마크에서도 인상적인 성과를 보이며, 이는 마지막 단계에서 지침 준수 데이터가 포함된 것과 관련이 있습니다.
요약 길이: DeepSeek-R1은 ArenaHard에서 평균 689 토큰, AlpacaEval 2.0에서 2,218 자라는 간결한 요약 길이를 생성합니다. 이는 GPT 기반 평가에서 길이 편향을 피하는 것을 나타냅니다.
5. 수학 및 코딩 작업:
수학 작업에서는 OpenAI-o1-1217과 비슷한 성능을 보이며, 다른 모델들보다 크게 우수합니다. LiveCodeBench와 Codeforces와 같은 코딩 알고리즘 작업에서도 추론 중심 모델이 우세합니다.
그러나 엔지니어링 관련 코딩 작업에서는 OpenAI-o1-1217이 Aider에서 DeepSeek-R1보다 우수하지만, SWE Verified에서는 비슷한 성능을 보입니다.
결론적으로, DeepSeek-R1은 여러 벤치마크에서 뛰어난 성능을 보이며, 특히 STEM 관련 질문과 장기 문맥 문제에서 강점을 가지고 있습니다. 그러나 특정 영역에서는 개선이 필요하며, 향후 버전에서 엔지니어링 성능이 더욱 향상될 것으로 기대됩니다.
그러면 딥시크는 오픈 AI 기업과 기술적으로 어떻게 다를까요~?
오픈 AI, 딥시크 R1 기술적 접근방식의 차이
1. OpenAI의 기술적 특징
- 대규모 언어 모델(LLM) 중심
- GPT 시리즈를 통한 지속적인 발전
- 방대한 데이터 기반의 사전학습 RLHF(Reinforcement Learning from Human Feedback) 적용
2. 딥시크 R1의 혁신적 접근
- 강화학습 중심의 설계
- 실시간 학습 및 적응 능력 강화
- 문제 해결 중심의 알고리즘
- 효율적인 리소스 활용
강화학습 AI vs 미세조정 및 사전학습 RLHF AI
여러분은 알파고가 어떻게 이세돌 9단을 이겼는지 궁금하신 적이 있나요? 또는 자율주행 자동차가 어떻게 복잡한 도로 상황에서 올바른 판단을 내리는지 생각해 보셨나요? 이 모든 것의 핵심에는 강화학습 AI가 있습니다.
강화학습(Reinforcement Learning)은 인공지능이 마치 인간처럼 시행착오를 통해 학습하는 방법입니다.
한 아이는 직접 자전거를 타면서 넘어지고 다치면서 배우고, 다른 아이는 먼저 자전거의 원리를 배우고 전문가의 조언을 들으며 배웁니다. 강화학습 AI와 미세조정과 사전학습 RLHF를 거친 AI의 차이는 바로 이런 학습 방식의 차이와 비슷합니다.
DeepMind Research에 따르면, 이 두 가지 접근 방식은 각각의 독특한 장점으로 AI 발전을 이끌고 있습니다.
강화학습 AI 란? Reinforcement Learning
강화학습은 AI가 직접 시행착오를 통해 학습하는 방식입니다. 마치 아이가 자전거를 타다가 넘어지면서 배우는 것처럼, AI는 아래와 같은 과정을 거칩니다.
- 환경과의 직접 상호작용
- 즉각적인 피드백 수신
- 시행착오를 통한 전략 개선
적용 분야
- 게임
- 로보틱스
- 자율주행
- 자원 관리 시스템
아래의 안될 과학 유튜브 채널에서 강화학습 AI에 대해 쉽게 설명한 콘텐츠가 있으니 궁금한 분들은 참고하여 주세요.
강화학습 AI 영상 살펴보기
사전학습 RLHF AI란? Reinforcement Learning from Human Feedback
ChatGPT나 Claude와 같은 AI 챗봇이 어떻게 인간처럼 자연스러운 대화가 가능할까요? 그 핵심에는 사전학습 RLHF(Reinforcement Learning from Human Feedback) AI 기술이 있습니다.
- 대규모 데이터로 사전학습
- 인간의 피드백을 통한 미세조정
- 윤리적 가이드라인 학습
적용분야
- 챗봇 (Chat GPT)
- 콘텐츠 생성
- 고객 서비스
- 코드 작성
사전학습 AI에 대한 설명은 아래의 유튜브 콘텐츠를 참고하여 주세요.
사전학습 AI 설명 살펴보기
앞으로의 AI 산업군 전망
딥시크 R1의 영향으로 앞으로 AI 산업군은 이렇게 변할 것으로 사료됩니다.
첫째로, 고성능 GPU의 필요로 인해 독점 고마진이었던 엔비디아의 가격 인하 가능성이 있습니다. 딥시크 R1과 같이 저 비용의 하드웨어로도 일정 수준의 발전이 가능하다는 것을 보여주었기 때문입니다.
두 번째로, AI 산업군은 이번 계기로 인해 본격적으로 경쟁이 가속화될 것으로 예상됩니다. 그러나 미국 거대 기업으로 이루어진 산업 기조는 유지될 것으로 보입니다.
세 번째로, 전체주의적인 중국 기업으로서의 한계로 딥시크는 개인정보 등의 투명하지 못한 우려점을 가지고 있습니다.
이러한 정황을 볼 때, 딥시크 R1의 강화학습 발전과 성능은 무시하지 못할 수준이지만, 범용성에 있어서는 앞으로 발전할 전반적인 AI 산업군에서의 하드웨어적인 한계점이 있어 보이며, AI 산업군에서의 미국 거대 기업 산업기조는 유지될 것으로 보입니다.
감사합니다.
'주식' 카테고리의 다른 글
| 방산주 관련주 및 대장주 TOP6 소개! 한화시스템 주가 급등 ?! (0) | 2025.02.12 |
|---|---|
| 딥시크 관련주 TOP5 소개 (0) | 2025.01.29 |
| 양자컴퓨터 관련주 TOP5 및 엔비디아 '젠슨황의 언급' 과연 전망은? (0) | 2025.01.09 |
| 브로드컴 ETF 추천 TOP4 (1) | 2025.01.04 |
| 브로드컴 관련주 대장주 TOP5 및 주가 전망은? (7) | 2025.01.01 |



